Web scraping and analysis of Goodreads book list
Web scraping Goodreads book list using Python and BeautifulSoup library along with quick data analysis in Python with pandas and matplotli
I was interested in what kinds of books are most often recommended in the most popular book list on Goodreads so I decided to use web scraping to gather information about top 100 books in Books That Everyone Should Read At Least Once . Below you can find all the information I decided to gather.
Project overview
- Created a tool for scraping data from Goodreads book lists
- Saved all the data in csv file
- Looked at the distribution of the data and analysed it, below are a few highlights from this data set.
Python version and packages used
Python Version: 3.8
Packages: pandas, numpy, matplotlib, seaborn, BeautifulSoup4
Web Scraping
During the web scraping part of this project I decided what information I want to scrape and what would give me an interesting insight into these lists. Below you can find all the information I decided to gather.
- Title
- Link
- Author
- Average rating
- Score
- Number of pages
- Genre
This data was then saved in csv file for further analysis. You can see commented python code here scraper.
Data Analysis
Since I scraped only the data I needed there was almost no need for data cleaning besides deleting one column containing links for specific book pages. I looked at the distribution of the data and the value counts for each category and found some interesting highlights.
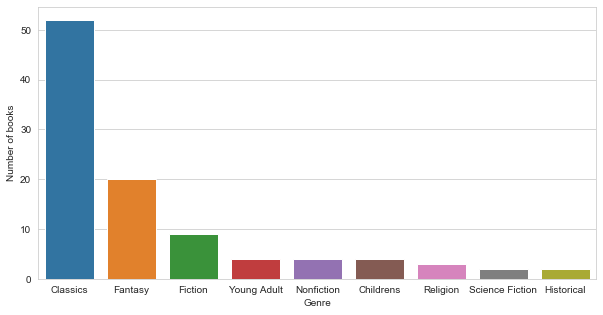
As expected most popular genres are classics and fantasy, these are very popular and a lot of people get into literature either thanks to classics in school or through fantasy which is another very popular genre.
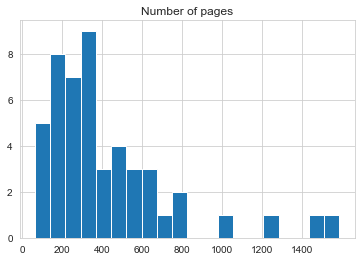
Most popular books are the ones with 200-400 pages, these books are ideal length for reading and from this it seems that very long books scare people away since its such a commitment to read a very long book.
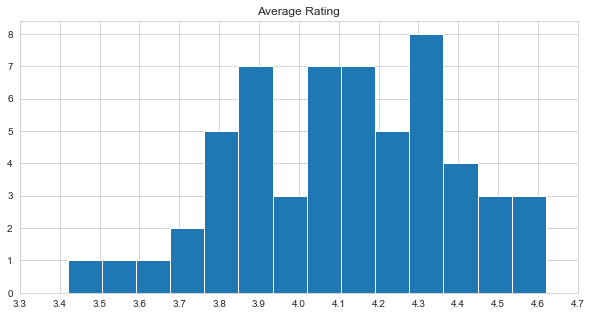
These books are well known and loved throughout generations but I expected little bit higher scores, this can be caused by their popularity, its bound to happen that even people who wouldn’t necessarily pick books like this on their own these because they are so popular but its not their cup of it which can lower overall rating.
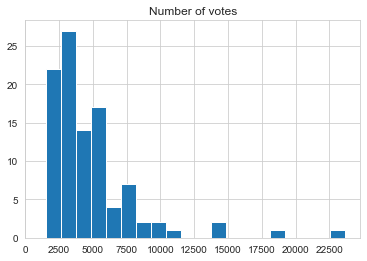
This one was surprising. I expected normal distribution but most of the books have lower ratings, this may be caused by outliers. If we would select only books with less votes than 12 000 we would get a more balanced distribution without low number of votes, because all of these books are popular and they are bound to have larger numbers of votes than the average number of votes for all the books on goodreads.
I also looked into correlation between the number of votes, average rating and number of pages with. Based on this books with higher number of votes have higher average rating and books with more pages have slightly lower number of votes but higher average rating. You can find more details in commented code here analysis